Deep into KV Cache
observations and learnings from the world of LLM inference
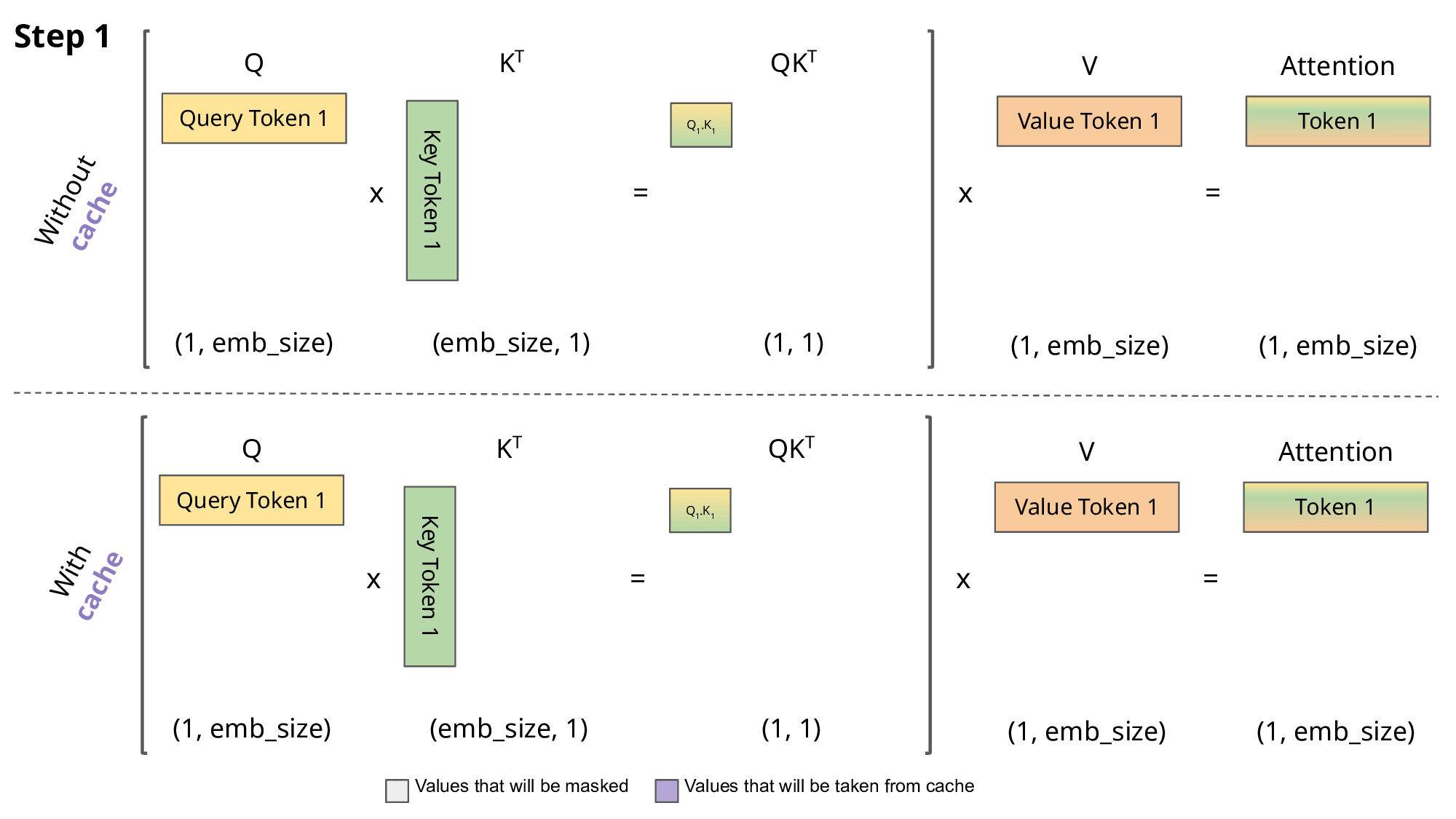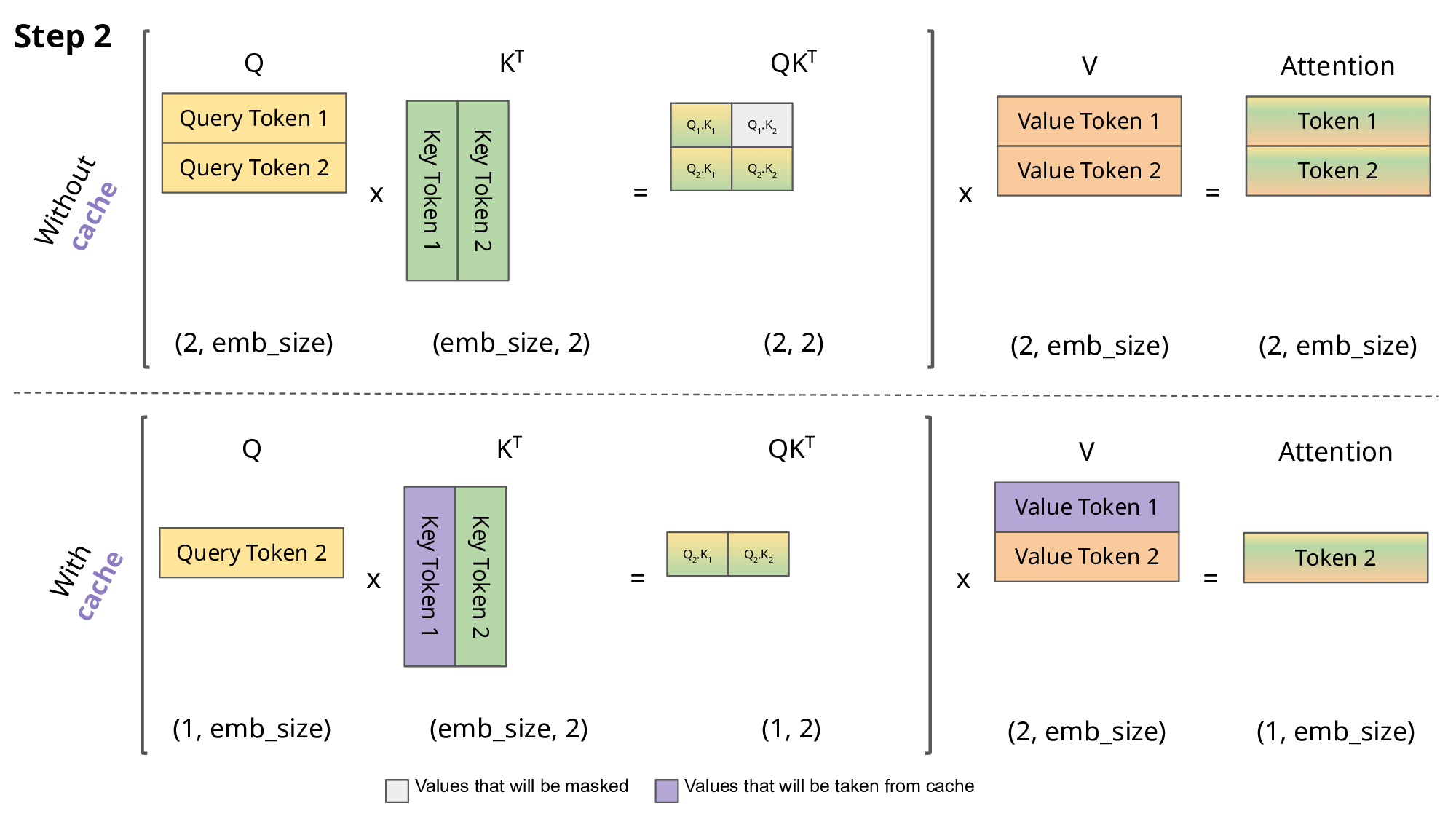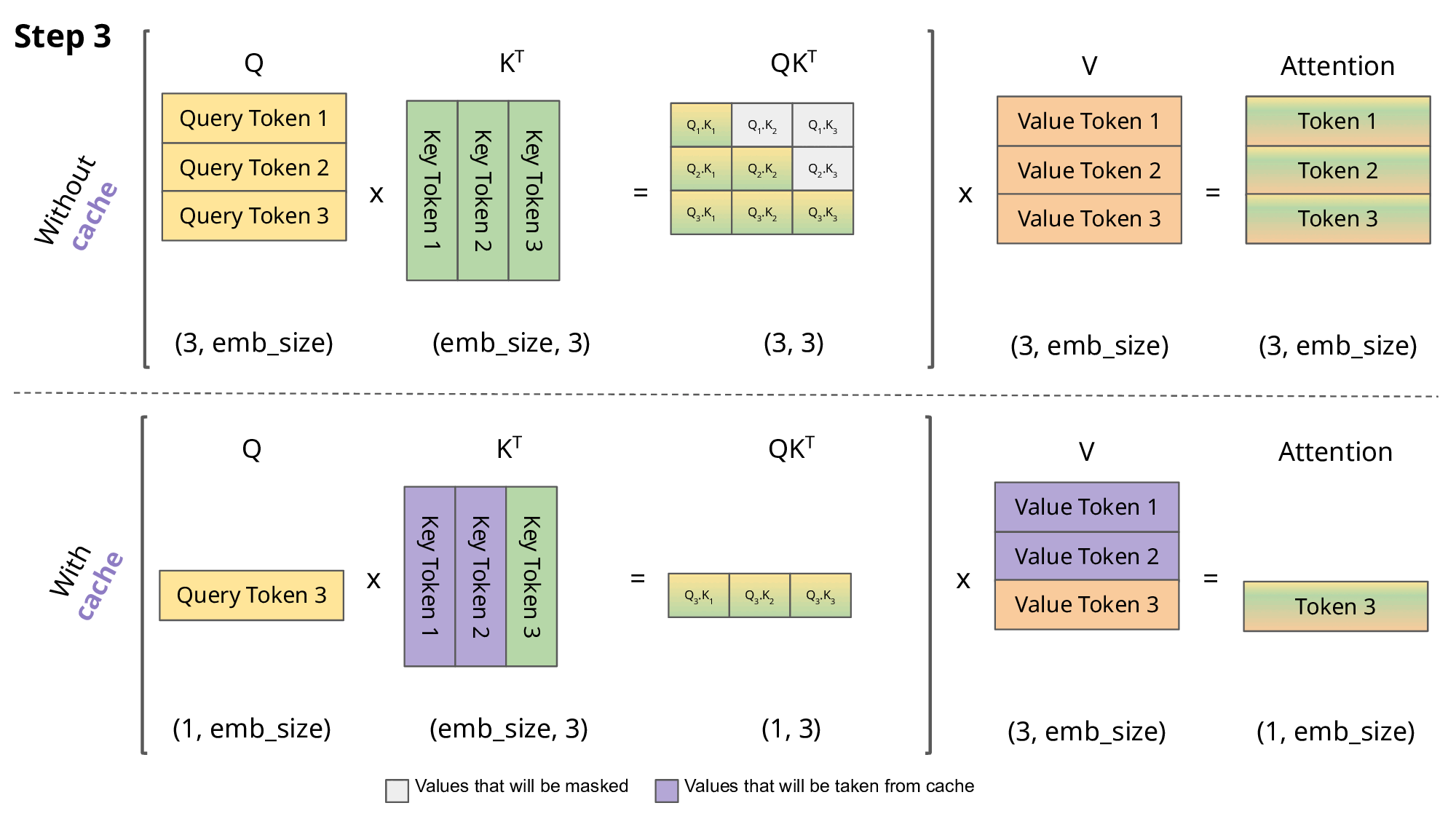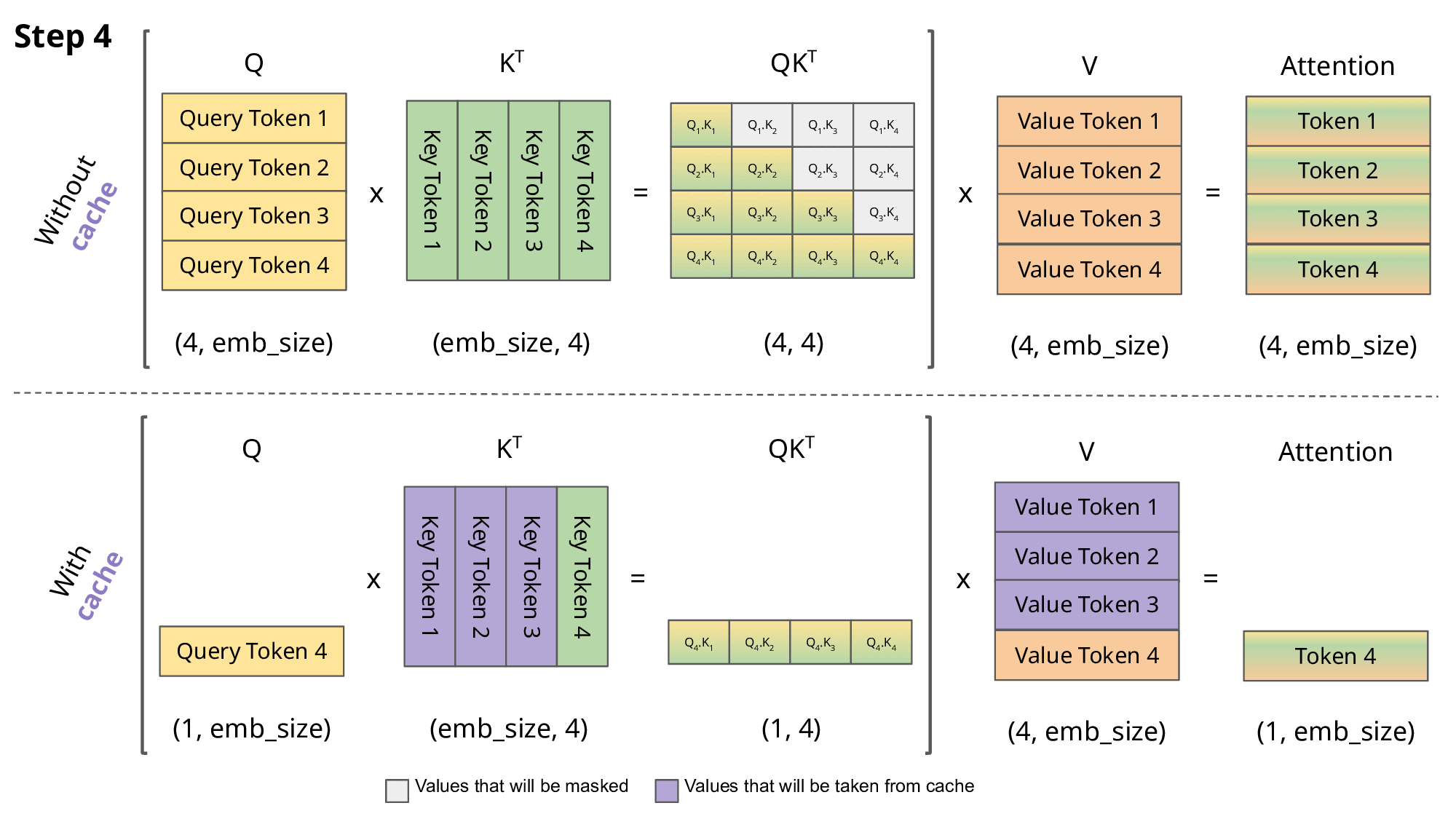
As seen in the picture above, the matrices obtained with KV caching are way smaller, which leads to faster matrix multiplications. The only downside is that it needs more GPU VRAM (or CPU RAM if GPU is not being used) to cache the Key and Value states.
Fortunately, contexts with identical prefixes can take advantage of KV-cache, which drastically reduces time-to-first-token (TTFT) and inference cost—whether you're using a self-hosted model or calling an inference API. And we're not talking about small savings: with Claude Sonnet, for instance, cached input tokens cost 0.30 USD/MTok, while uncached ones cost 3 USD/MTok—a 10x difference.
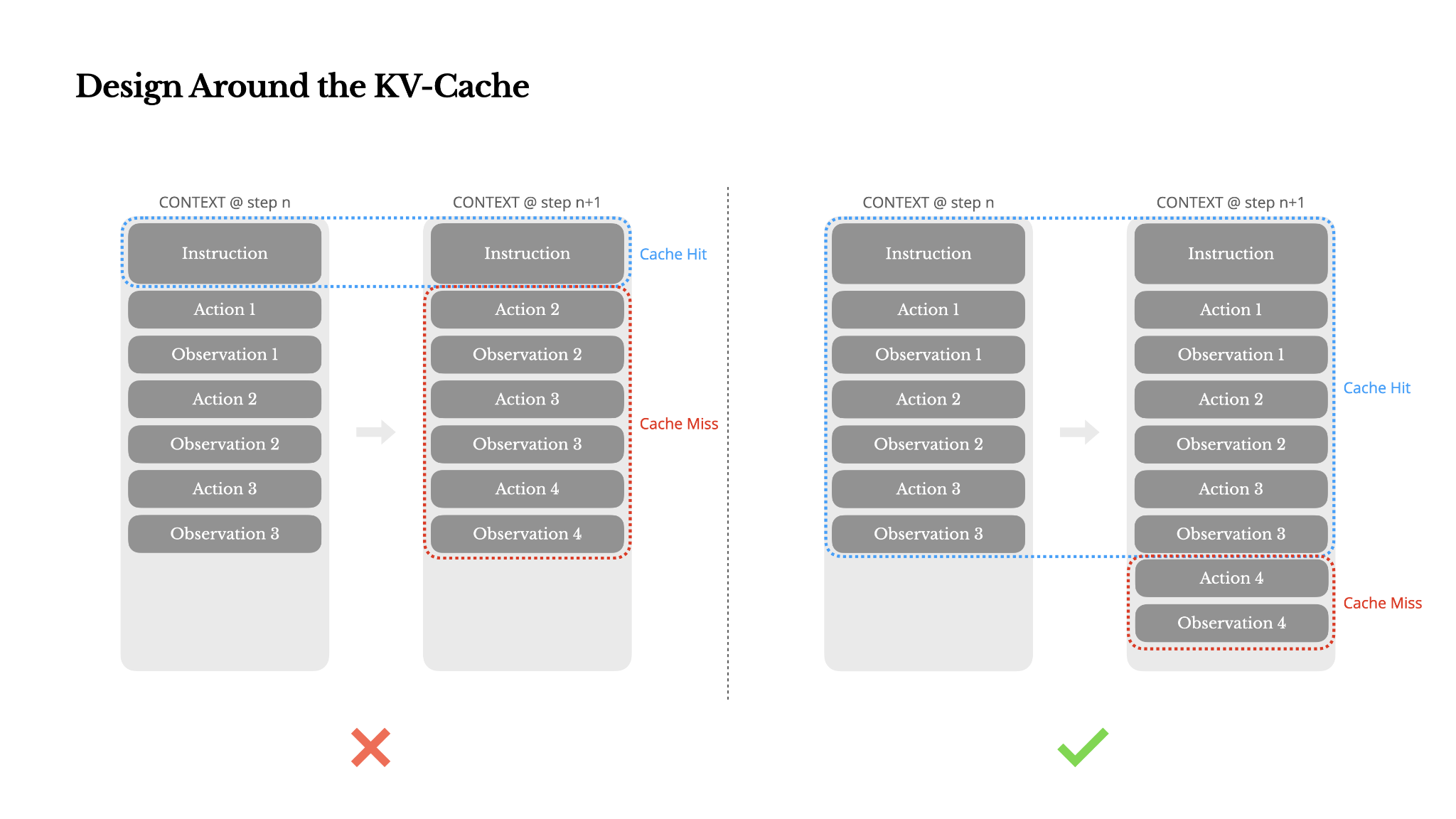
Improving KV-Cache Hit Rate
From a context engineering perspective, improving KV-cache hit rate involves a few key practices:
- Keep your prompt prefix stable. Due to the autoregressive nature of LLMs, even a single-token difference can invalidate the cache from that token onward. A common mistake is including a timestamp—especially one precise to the second—at the beginning of the system prompt. Sure, it lets the model tell you the current time, but it also kills your cache hit rate.
- Make your context append-only. Avoid modifying previous actions or observations. Ensure your serialization is deterministic. Many programming languages and libraries don't guarantee stable key ordering when serializing JSON objects, which can silently break the cache.
- Mark cache breakpoints explicitly when needed. Some model providers or inference frameworks don't support automatic incremental prefix caching, and instead require manual insertion of cache breakpoints in the context. When assigning these, account for potential cache expiration and at minimum, ensure the breakpoint includes the end of the system prompt.
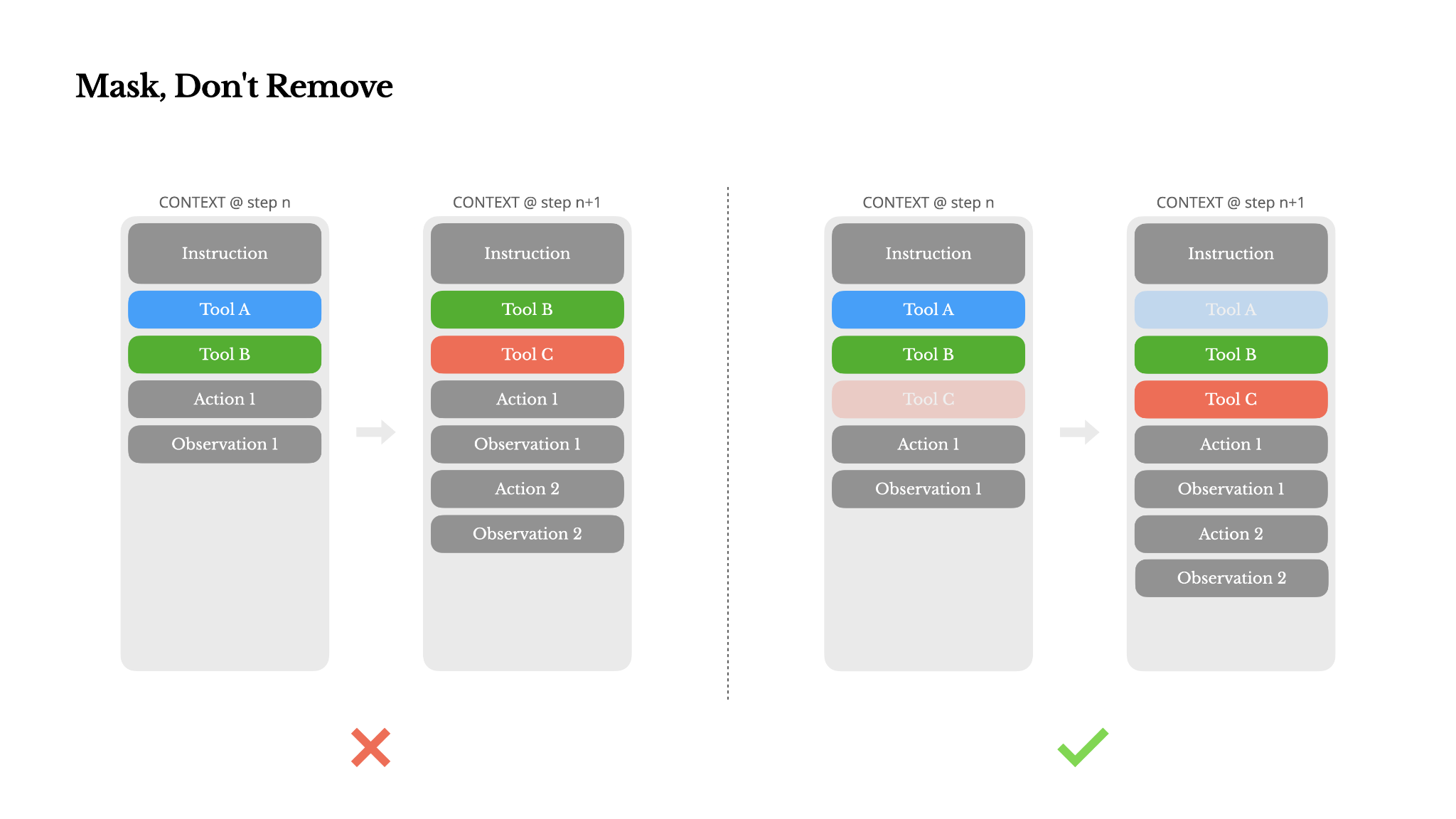
Avoid Dynamic Tool Changes
Unless absolutely necessary, avoid dynamically adding or removing tools mid-iteration. There are two main reasons for this:
- In most LLMs, tool definitions live near the front of the context after serialization, typically before or after the system prompt. So any change will invalidate the KV-cache for all subsequent actions and observations.
- When previous actions and observations still refer to tools that are no longer defined in the current context, the model gets confused. Without constrained decoding, this often leads to schema violations or hallucinated actions.
Context Window Limitations
Modern frontier LLMs now offer context windows of 128K tokens or more. But in real-world agentic scenarios, that's often not enough, and sometimes even a liability. There are three common pain points:
- Observations can be huge, especially when agents interact with unstructured data like web pages or PDFs. It's easy to blow past the context limit.
- Model performance tends to degrade beyond a certain context length, even if the window technically supports it.
- Long inputs are expensive, even with prefix caching. You're still paying to transmit and prefill every token.
The problem is fundamental: an agent, by nature, must predict the next action based on all prior state—and you can't reliably predict which observation might become critical ten steps later. From a logical standpoint, any irreversible compression carries risk.
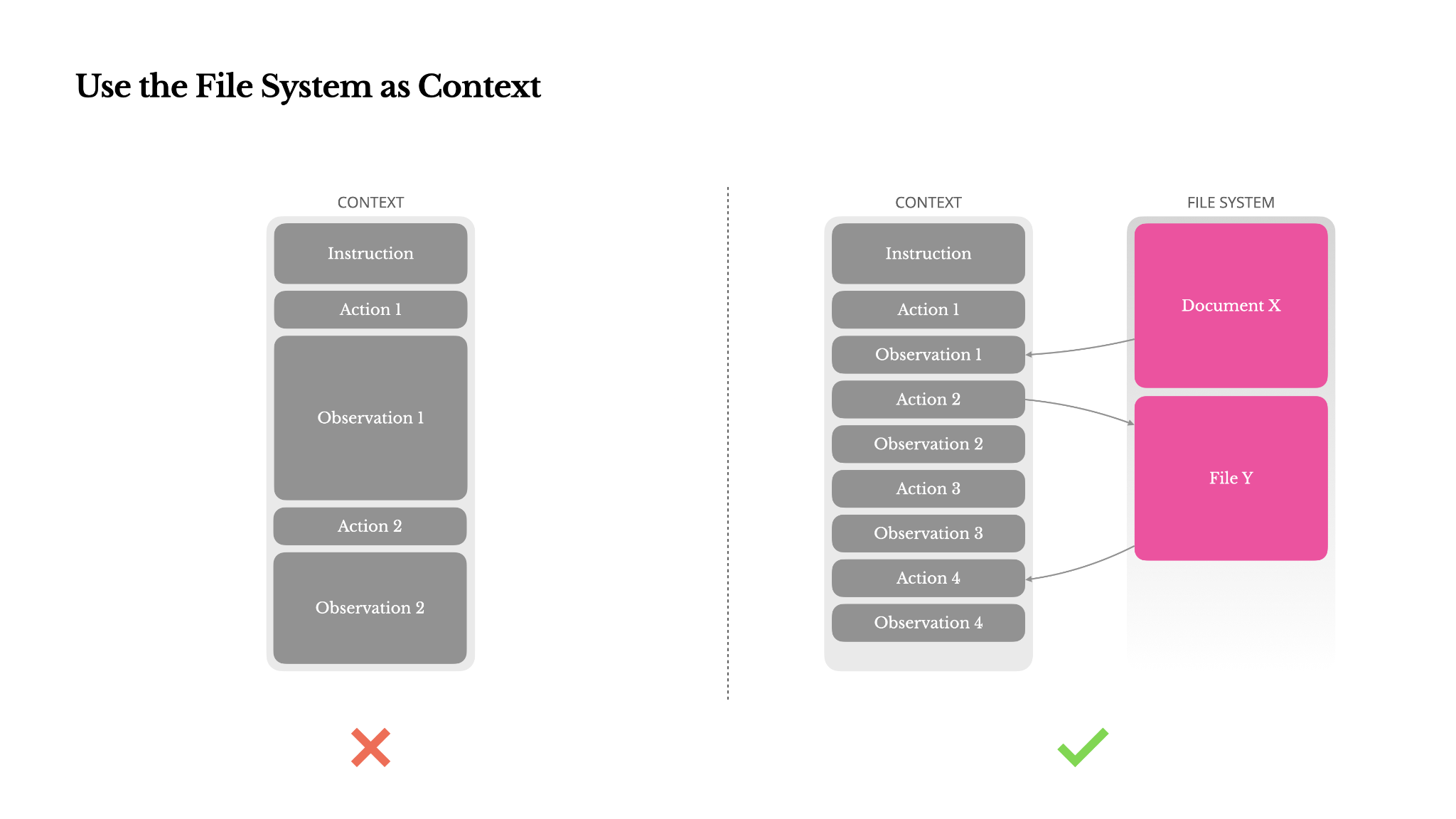
The File System as Context
The file system as the ultimate context in Manus: unlimited in size, persistent by nature, and directly operable by the agent itself. The model learns to write to and read from files on demand—using the file system not just as storage, but as structured, externalized memory.
Leave Wrong Turns in Context
Leave the wrong turns in the context. When the model sees a failed action—and the resulting observation or stack trace—it implicitly updates its internal beliefs. This shifts its prior away from similar actions, reducing the chance of repeating the same mistake.

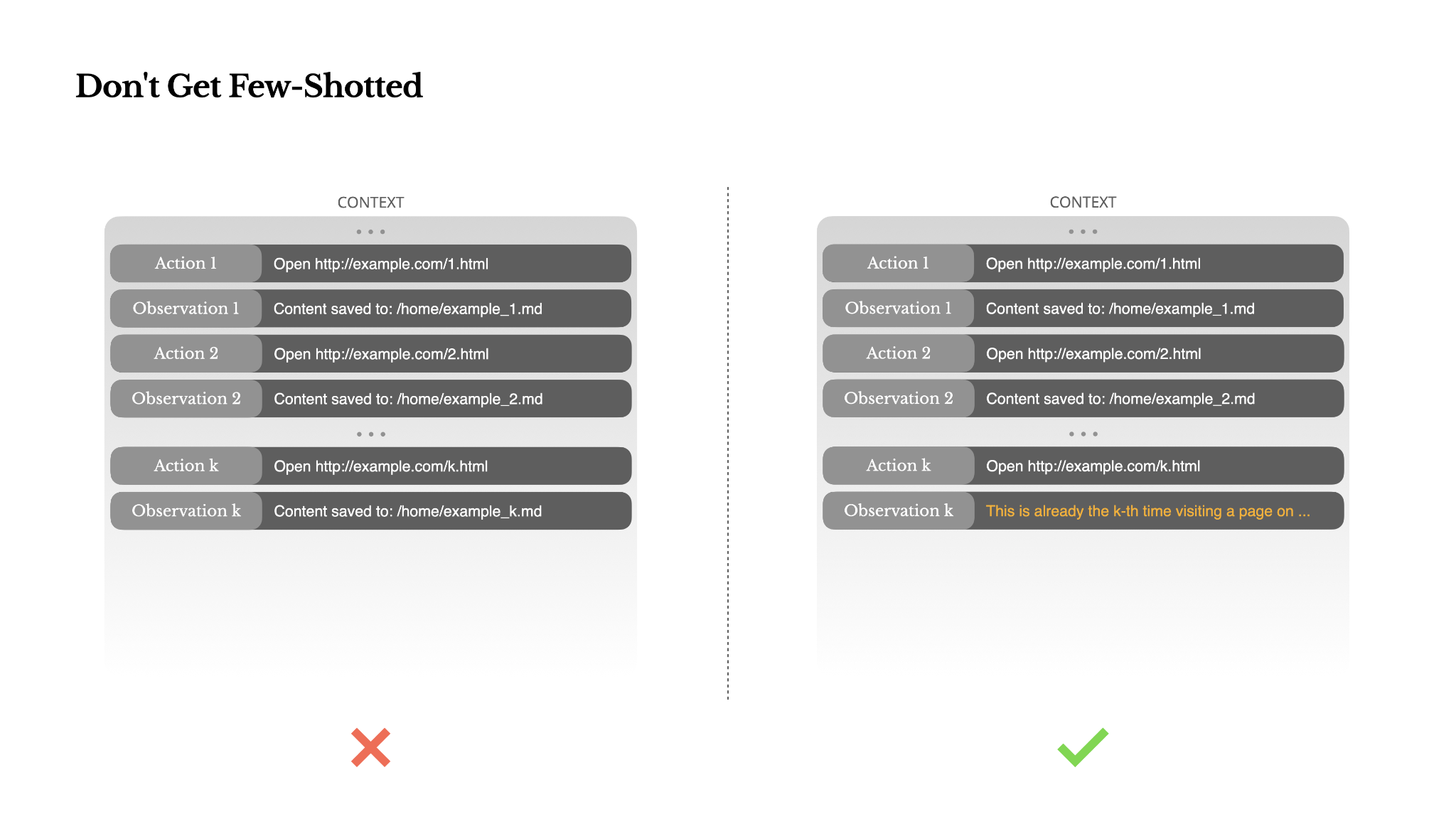
Don't Get Few-Shotted
Few-shot prompting is a common technique for improving LLM outputs. But in agent systems, it can backfire in subtle ways. Language models are excellent mimics; they imitate the pattern of behavior in the context. If your context is full of similar past action-observation pairs, the model will tend to follow that pattern, even when it's no longer optimal.
The fix is to increase diversity. Manus introduces small amounts of structured variation in actions and observations—different serialization templates, alternate phrasing, minor noise in order or formatting. This controlled randomness helps break the pattern and tweaks the model's attention. In other words, don't few-shot yourself into a rut. The more uniform your context, the more brittle your agent becomes.